

首先丢过来传统正则表达式
[u4e00-u9fa5] 或 [一-龥]
u4e00:一
u9fa5:龥
还有两个:[一-龟]和[一-龙],基本可以平替
中文字符集编码表里面,Unicode以u开头,第一个汉字是“4e00”(一),因为古文里面一就是万物之始。
“一”字本义是表示最小的正整数。 《玉篇·一部》:“一, 王弼 曰:一者,数之始也。 ”又表示序数,指第一。 《书·洪范》:“五行:一曰水,二曰火,三曰木,四曰金,五曰土。 ” 金文 、篆文承续甲骨文字形。 春秋战国 以后,“一”字又可写作“弌”或“弌”,累增“弋”或“戈”旁,是一种繁化写法。 后世这种繁化写法均被废弃。 最小的正整数;常用以表示人或事、物的最少数量。 一也者,万物之本也。 ——《淮南子 ·诠言》 抱一而天下试。 ——《老子》 故一人有事于四方。 ——《尚书 · 君奭》 序数的第一位。 一战而举鄢、郢。 ——《史记 ·平原君虞卿列传》 若干份中的一份或整数以外的零头。 先王之制,大都不过参国之一,中五之一,小九之一。 ——《左传》
最后一个汉字是“9fa0”(龥) ,这样写了个程序浅浅统计了一下,如果不考虑极少数不可见汉字,那么总共有20901个汉字。
常见中文里面最后五个汉字:
龠 (u9fa0)
龡 (u9fa1)
龢 (u9fa2)
龣 (u9fa3)
龤 (u9fa4)
龥 (u9fa5)
另外一说,u9fa1到u9fbb有27个汉字,u9fa1到u9fef还有79个汉字。但u9fbb之后字形不可见。而且还有一些字,在GBK里面,但是无法显示。举个直白的例子,带口的当。
由于《简化字总表》中「噹」和「當」合并为「当」,在748工程中进行的字频统计里自然只会有「当」的字频,加上《简化字总表》使得 GB/T 2312-1980 中不会出现「⿰口当」字。又由于这是个简化字,所以其它国家和地区也不会提交这个字,从而 URO 中不会有这个字。
「⿰口当」这个字被收入 Unicode,或者说 ISO/IEC 10646,或者说 GB/T 13000,是在扩充 C 块内。由于当时对每个被提交的汉字有了「讲证据」的要求,中国方面对所有用字大头提交来的汉字进行审查,并筛选出有证据的汉字加以提交,其中就包括「⿰口当」字。
说白了,就是这个字存在过,在GBK里面也有这个字,但是现在悄无声息的从Unicode里面删除了。
更多的范围见:4E00-9FEF、3400-4DB5、20000-2FA1D和2E80-2FD5,其中有一些字形不可见。
如何快速调用
使用优化过的表达式
采用[一-龟]或者[一-龙]替换,这俩字更好记,更好打出来。只要是不打什么偏僻的文言文,基本管用。
使用传统表达式
在金山文字或者微软Word里面输入9FA5, 选中这四位编码,用快捷键【alt+x】可以把16进制Unicode代码转化为这个汉字。
或者来点更离谱的:在金山文字/微软Word中选择【插入】——【符号】——选择【CJK兼容汉字】就能很快定位到这个龥。
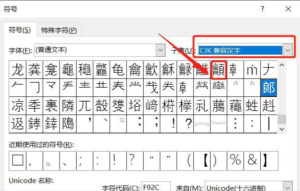
再来点离谱的,如果会五笔的话,用五笔【wgkm】可以打出此字。各位八零九零后是不是DNA动了?
怎么样?是不是会用了?
王旁青头戋五一土士二干十寸雨大犬三羊古石厂工戈草头右框七






暂无评论内容