用Python一键删除PDF中的所有图片
前言
24年10制作了个PDF,利用亿方教材助手把五四制语文初一到初四的所有需要背诵的古文古诗合并为一个PDF,但是由于家里的打印机是黑白的,打印图片又大量废黑色墨水,就想着把所有图片全删了,但是一个一个删除太麻烦,于是就想着借助Python把所有的图片批量删除,随手去搜了一下发现真的可以,借助强大的PyMuPDF库就可以实现,好的,话不多说上代码!
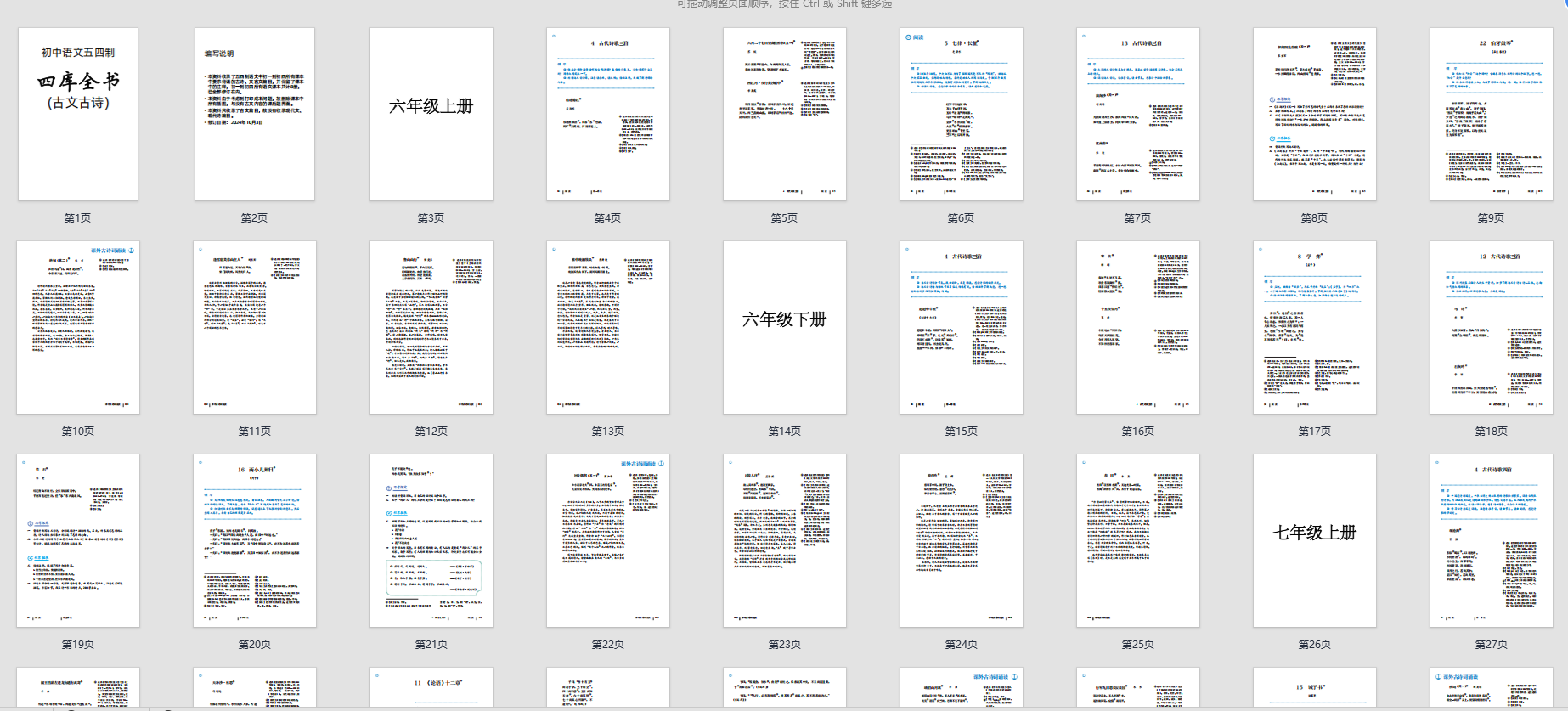
(如上,没有任何一张插图)
代码
安装PyMuPDF库
打开终端,输入以下代码安装PyMuPDF库:
pip install pymupdf -i https://pypi.tuna.tsinghua.edu.cn/simple
Python代码
import fitz # 使用的是 PyMuPDF 库
import os
def remove_images_from_pdf(input_pdf_path, output_pdf_path):
# 打开 PDF 文件
pdf_document = fitz.open(input_pdf_path)
# 遍历每一页
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
# 查找并删除页面中的所有图片
image_list = page.get_images(full=True)
for img in image_list:
xref = img[0]
page.delete_image(xref)
# 保存修改后的 PDF 文件
pdf_document.save(output_pdf_path)
pdf_document.close()
def batch_remove_images_from_pdfs(input_folder):
# 获取当前运行脚本的目录作为输出文件夹
output_folder = os.getcwd()
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历输入文件夹中的所有 PDF 文件
for pdf_file in os.listdir(input_folder):
if pdf_file.lower().endswith(".pdf"):
input_pdf_path = os.path.join(input_folder, pdf_file)
output_pdf_path = os.path.join(output_folder, pdf_file)
# 移除图片并保存修改后的 PDF 文件
remove_images_from_pdf(input_pdf_path, output_pdf_path)
print(f"已从{input_pdf_path}中删除图像并保存到{output_pdf_path}")
if __name__ == "__main__":
input_folder = r"C:/Users/xuanli/Desktop/pdf" # 替换为您的输入文件夹路径
batch_remove_images_from_pdfs(input_folder)提醒一下:最后倒数第二行的文件夹路径记得改为自己实际的PDF文件存放文件夹,毕竟你又没借玄离的电脑哈哈哈(这代码真不是玄离199给我写的,只是玩下梗哈哈)
阅读剩余
版权声明:
作者:小杨聊科技
链接:https://www.yxxblog.top/software/delete-all-pdf-images-by-python.html
文章版权归作者所有,未经允许请勿转载。
THE END